LLM Course documentation
သင့်ကိုယ်ပိုင် Dataset တစ်ခု ဖန်တီးခြင်း
သင့်ကိုယ်ပိုင် Dataset တစ်ခု ဖန်တီးခြင်း

တခါတရံမှာ သင် NLP application တစ်ခု တည်ဆောက်ဖို့ လိုအပ်တဲ့ dataset ဟာ မရှိနေတတ်ပါဘူး။ ဒါကြောင့် သင်ကိုယ်တိုင် ဖန်တီးဖို့ လိုအပ်ပါလိမ့်မယ်။ ဒီအပိုင်းမှာ GitHub repository တွေမှာ bugs တွေ ဒါမှမဟုတ် features တွေကို ခြေရာခံရာမှာ အသုံးများတဲ့ GitHub issues တွေကို corpus တစ်ခုအနေနဲ့ ဘယ်လိုဖန်တီးရမလဲဆိုတာကို ပြသပေးပါမယ်။ ဒီ corpus ကို ရည်ရွယ်ချက်အမျိုးမျိုးအတွက် အသုံးပြုနိုင်ပါတယ်။
- ပွင့်နေတဲ့ issues ဒါမှမဟုတ် pull requests တွေကို ပိတ်ဖို့ ဘယ်လောက်ကြာသလဲဆိုတာကို လေ့လာခြင်း
- issue ရဲ့ ဖော်ပြချက်ပေါ်မူတည်ပြီး metadata (ဥပမာ- “bug,” “enhancement,” သို့မဟုတ် “question”) နဲ့ tag လုပ်နိုင်တဲ့ multilabel classifier တစ်ခုကို training လုပ်ခြင်း
- အသုံးပြုသူရဲ့ query နဲ့ ကိုက်ညီတဲ့ issues တွေကို ရှာဖွေဖို့ semantic search engine တစ်ခု ဖန်တီးခြင်း
ဒီနေရာမှာ ကျွန်တော်တို့ corpus ဖန်တီးတာကို အဓိကထားပြီး၊ နောက်အပိုင်းမှာတော့ semantic search application ကို လေ့လာပါမယ်။ အကြောင်းအရာကို ပိုမိုနားလည်လွယ်အောင်၊ လူကြိုက်များတဲ့ open source project တစ်ခုဖြစ်တဲ့ 🤗 Datasets နဲ့ ဆက်စပ်နေတဲ့ GitHub issues တွေကို အသုံးပြုပါမယ်! data ကို ဘယ်လိုရယူရမလဲ၊ ဒီ issues တွေမှာ ပါဝင်တဲ့ အချက်အလက်တွေကို ဘယ်လိုလေ့လာရမလဲဆိုတာ ကြည့်ရအောင်။
Data ကို ရယူခြင်း
🤗 Datasets မှာရှိတဲ့ issues အားလုံးကို repository ရဲ့ Issues tab ကို သွားပြီး ရှာဖွေနိုင်ပါတယ်။ အောက်ပါ screenshot မှာ ပြထားတဲ့အတိုင်း၊ ဒီစာကို ရေးသားနေချိန်မှာ ပွင့်နေတဲ့ issues ၃၃၁ ခုနဲ့ ပိတ်ထားတဲ့ issues ၆၆၈ ခု ရှိပါတယ်။

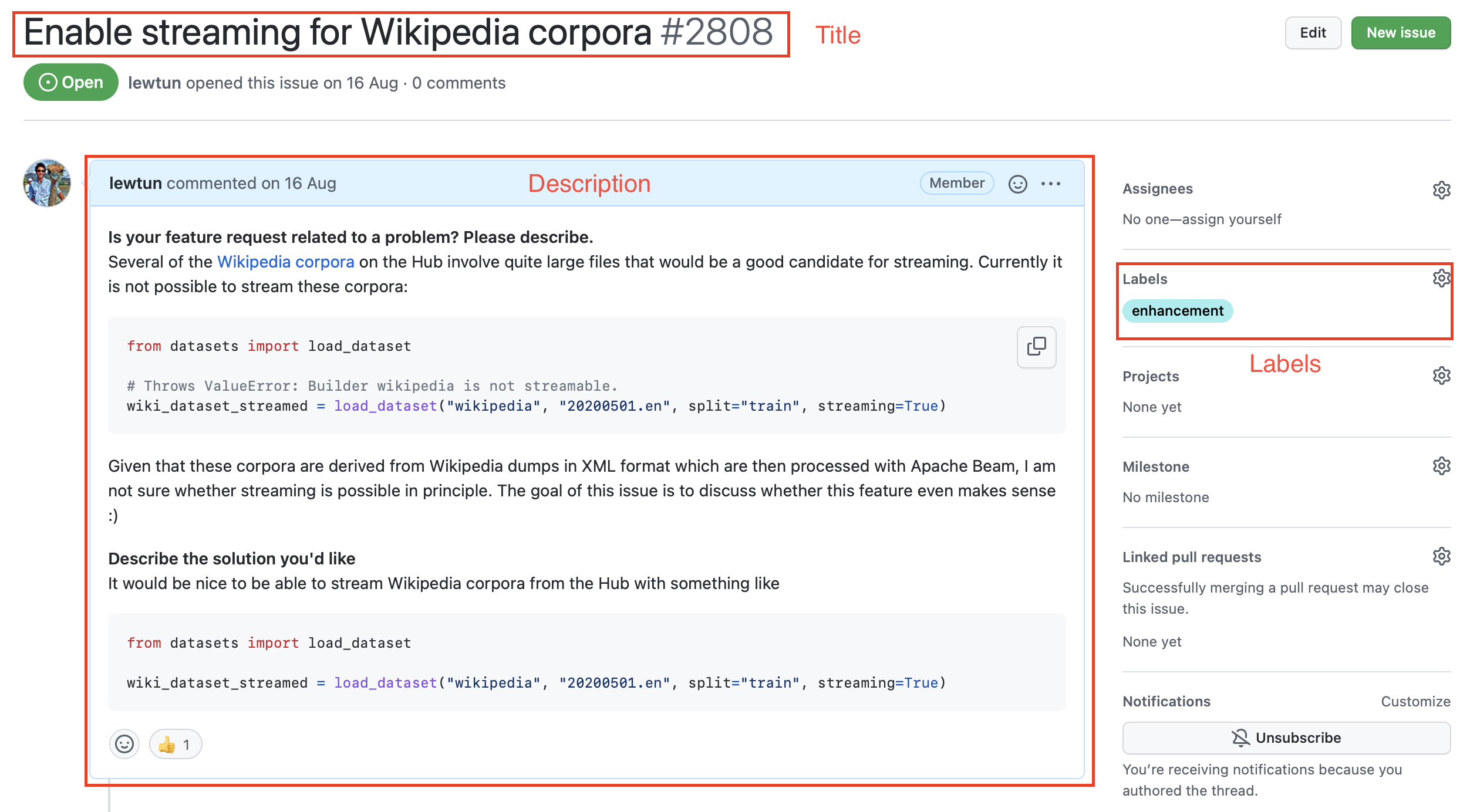
ဒီ issues တွေထဲက တစ်ခုကို နှိပ်လိုက်ရင် title၊ description နဲ့ issue ကို ဖော်ပြတဲ့ labels အစုအဝေးတစ်ခု ပါဝင်တာကို သင်တွေ့ရပါလိမ့်မယ်။ ဥပမာတစ်ခုကို အောက်ပါ screenshot မှာ ပြသထားပါတယ်။
repository ရဲ့ issues အားလုံးကို download လုပ်ဖို့၊ Issues endpoint ကို poll လုပ်ဖို့ GitHub REST API ကို အသုံးပြုပါမယ်။ ဒီ endpoint က JSON objects စာရင်းတစ်ခုကို ပြန်ပေးပြီး၊ object တစ်ခုစီမှာ title နဲ့ description အပြင် issue ရဲ့ status နဲ့ အခြား metadata အများအပြား ပါဝင်ပါတယ်။
issues တွေကို download လုပ်ဖို့ အဆင်ပြေတဲ့ နည်းလမ်းတစ်ခုကတော့ requests library ကို အသုံးပြုခြင်းပါပဲ။ ဒါက Python မှာ HTTP requests တွေ ပြုလုပ်ဖို့အတွက် standard နည်းလမ်းတစ်ခုပါ။ library ကို အောက်ပါအတိုင်း install လုပ်နိုင်ပါတယ်။
!pip install requests
library ကို install လုပ်ပြီးတာနဲ့၊ requests.get() function ကို ခေါ်ခြင်းဖြင့် Issues endpoint ကို GET requests တွေ ပြုလုပ်နိုင်ပါတယ်။ ဥပမာအားဖြင့်၊ ပထမစာမျက်နှာရဲ့ ပထမဆုံး issue ကို ပြန်လည်ရယူဖို့ အောက်ပါ command ကို run နိုင်ပါတယ်။
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)response object က HTTP status code အပါအဝင် request နဲ့ပတ်သက်တဲ့ အသုံးဝင်တဲ့ အချက်အလက်များစွာ ပါဝင်ပါတယ်။
response.status_code
200ဒီနေရာမှာ 200 status က request အောင်မြင်တယ်လို့ ဆိုလိုပါတယ် (ဖြစ်နိုင်ချေရှိတဲ့ HTTP status codes စာရင်းကို ဒီနေရာမှာ ရှာတွေ့နိုင်ပါတယ်။) ကျွန်တော်တို့ တကယ်စိတ်ဝင်စားတာက payload ဖြစ်ပြီး၊ ဒါကို bytes, strings, သို့မဟုတ် JSON လိုမျိုး formats မျိုးစုံနဲ့ ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။ ကျွန်တော်တို့ issues တွေက JSON format နဲ့ဆိုတာ သိတဲ့အတွက်၊ payload ကို အောက်ပါအတိုင်း စစ်ဆေးကြည့်ရအောင်။
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]အိုး၊ အချက်အလက်တွေ အများကြီးပါပဲ။ issue ကို ဖော်ပြတဲ့ title, body, နဲ့ number လိုမျိုး အသုံးဝင်တဲ့ fields တွေအပြင် issue ကို ဖွင့်ခဲ့တဲ့ GitHub user အကြောင်း အချက်အလက်တွေကိုလည်း ကျွန်တော်တို့ မြင်တွေ့ရပါတယ်။
✏️ စမ်းသပ်ကြည့်ပါ။ အပေါ်က JSON payload ထဲက URL အချို့ကို နှိပ်ပြီး GitHub issue တစ်ခုစီက ဘယ်လိုအချက်အလက်မျိုးတွေနဲ့ ချိတ်ဆက်ထားလဲဆိုတာကို ခံစားကြည့်ပါ။
GitHub documentation မှာ ဖော်ပြထားတဲ့အတိုင်း၊ authentication မလုပ်ထားတဲ့ requests တွေကို တစ်နာရီလျှင် 60 requests သာ ကန့်သတ်ထားပါတယ်။ သင် per_page query parameter ကို တိုးမြှင့်ခြင်းဖြင့် သင်ပြုလုပ်တဲ့ requests အရေအတွက်ကို လျှော့ချနိုင်ပေမယ့်၊ issues ထောင်ပေါင်းများစွာရှိတဲ့ repository တွေမှာတော့ rate limit ကို ကျော်လွန်နေဦးမှာပါ။ ဒါကြောင့်၊ သင်ဟာ တစ်နာရီလျှင် 5,000 requests အထိ rate limit ကို မြှင့်တင်နိုင်ဖို့ personal access token တစ်ခု ဖန်တီးဖို့ GitHub ရဲ့ ညွှန်ကြားချက်များ ကို လိုက်နာသင့်ပါတယ်။ သင့် token ရပြီဆိုတာနဲ့ request header ထဲမှာ ထည့်သွင်းနိုင်ပါတယ်။
GITHUB_TOKEN = xxx # သင့် GitHub token ကို ဒီနေရာမှာ ကူးထည့်ပါ။
headers = {"Authorization": f"token {GITHUB_TOKEN}"}⚠️ သင့်
GITHUB_TOKENကို ကူးထည့်ထားတဲ့ notebook ကို မျှဝေခြင်း မပြုပါနဲ့။ ဒီအချက်အလက်တွေ မတော်တဆ ပေါက်ကြားတာမျိုး မဖြစ်အောင်၊ သင် run ပြီးတာနဲ့ နောက်ဆုံး cell ကို ဖျက်ပစ်ဖို့ ကျွန်တော်တို့ အကြံပြုပါတယ်။ ပိုကောင်းတာကတော့ token ကို .env file ထဲမှာ သိမ်းဆည်းထားပြီး environment variable တစ်ခုအနေနဲ့ အလိုအလျောက် load လုပ်ပေးဖို့python-dotenvlibrary ကို အသုံးပြုပါ။
access token ရရှိပြီဆိုတာနဲ့၊ GitHub repository တစ်ခုကနေ issues အားလုံးကို download လုပ်နိုင်တဲ့ function တစ်ခု ဖန်တီးကြည့်ရအောင်။
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # စာမျက်နှာတစ်ခုစီတွင် ပြန်ပေးမည့် issues အရေအတွက်
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# state=all နဲ့ query လုပ်ပြီး open နဲ့ closed issues နှစ်ခုလုံးကို ရယူပါ
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # နောက်တစ်ကြိမ်အတွက် batch ကို ရှင်းပါ
print(f"GitHub rate limit ရောက်ပါပြီ။ တစ်နာရီကြာ အိပ်ပါမည် ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"{repo} အတွက် issues အားလုံးကို download လုပ်ပြီးပါပြီ! Dataset ကို {issues_path}/{repo}-issues.jsonl မှာ သိမ်းဆည်းထားပါတယ်"
)အခု fetch_issues() ကို ခေါ်လိုက်တဲ့အခါ GitHub ရဲ့ တစ်နာရီ requests အရေအတွက် ကန့်သတ်ချက်ကို မကျော်လွန်စေဖို့ issues အားလုံးကို batches အလိုက် download လုပ်ပါလိမ့်မယ်။ ရလဒ်ကို repository_name-issues.jsonl file ထဲမှာ သိမ်းဆည်းထားမှာဖြစ်ပြီး၊ line တစ်ကြောင်းစီက issue တစ်ခုကို ကိုယ်စားပြုတဲ့ JSON object တစ်ခု ဖြစ်ပါတယ်။ ဒီ function ကို အသုံးပြုပြီး 🤗 Datasets ကနေ issues အားလုံးကို ရယူလိုက်ရအောင်။
# သင့်အင်တာနက်ချိတ်ဆက်မှုပေါ်မူတည်ပြီး၊ ဒါက မိနစ်အနည်းငယ် ကြာနိုင်ပါတယ်...
fetch_issues()issues တွေကို download လုပ်ပြီးတာနဲ့ အပိုင်း ၂ ကနေ ကျွန်တော်တို့ရဲ့ အသစ်တွေ့ရှိတဲ့ ကျွမ်းကျင်မှုတွေကို အသုံးပြုပြီး ၎င်းတို့ကို locally load လုပ်နိုင်ပါတယ်-
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})ကောင်းပါပြီ၊ ကျွန်တော်တို့ရဲ့ ပထမဆုံး dataset ကို အစကနေ ဖန်တီးခဲ့ပါပြီ။ ဒါပေမယ့် 🤗 Datasets repository ရဲ့ Issues tab မှာ စုစုပေါင်း issues ၁,၀၀၀ ခန့်သာ ပြသနေပေမယ့် ဘာကြောင့် issues ထောင်ပေါင်းများစွာ ရှိနေရတာလဲ 🤔။ GitHub documentation မှာ ဖော်ပြထားတဲ့အတိုင်း၊ ကျွန်တော်တို့ pull requests တွေအားလုံးကိုပါ download လုပ်ထားလို့ပါပဲ။
GitHub ရဲ့ REST API v3 က pull request တိုင်းကို issue တစ်ခုလို့ သတ်မှတ်ပေမယ့်၊ issue တိုင်းကတော့ pull request မဟုတ်ပါဘူး။ ဒါကြောင့်၊ “Issues” endpoints တွေက response မှာ issues နဲ့ pull requests နှစ်ခုလုံးကို ပြန်ပေးနိုင်ပါတယ်။
pull_requestkey နဲ့ pull requests တွေကို ခွဲခြားသိမြင်နိုင်ပါတယ်။ “Issues” endpoints တွေကနေ ပြန်လာတဲ့ pull request တစ်ခုရဲ့idက issue id တစ်ခု ဖြစ်နေမှာကို သတိထားပါ။
issues နဲ့ pull requests ရဲ့ အကြောင်းအရာတွေက အတော်လေး ကွာခြားတာကြောင့်၊ ၎င်းတို့ကြား ခွဲခြားနိုင်ဖို့ minor preprocessing အချို့ လုပ်ကြည့်ရအောင်။
Data ကို သန့်ရှင်းရေးလုပ်ခြင်း
GitHub ရဲ့ documentation က အပေါ်က snippet က pull_request column ကို issues နဲ့ pull requests တွေကြား ခွဲခြားဖို့ အသုံးပြုနိုင်တယ်လို့ ကျွန်တော်တို့ကို ပြောပြပါတယ်။ ခြားနားချက်ကို မြင်နိုင်ဖို့ random sample တစ်ခုကို ကြည့်ရအောင်။ အပိုင်း ၃ မှာ လုပ်ခဲ့သလိုပဲ၊ Dataset.shuffle() နဲ့ Dataset.select() ကို တွဲပြီး random sample တစ်ခုကို ဖန်တီးပါမယ်။ ပြီးတော့ html_url နဲ့ pull_request columns တွေကို zip လုပ်ပြီး URLs တွေကို နှိုင်းယှဉ်နိုင်ပါလိမ့်မယ်။
sample = issues_dataset.shuffle(seed=666).select(range(3))
# URL နဲ့ pull request entries တွေကို print ထုတ်ပါ
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850', 'patch_url': 'https://github.com/huggingface/datasets/pull/850'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783', 'patch_url': 'https://github.com/huggingface/datasets/pull/783'}ဒီနေရာမှာ pull request တစ်ခုစီဟာ URLs မျိုးစုံနဲ့ ဆက်စပ်နေတာကို မြင်နိုင်ပြီး၊ သာမန် issues တွေမှာတော့ None entry ပါဝင်ပါတယ်။ ဒီခြားနားချက်ကို အသုံးပြုပြီး pull_request field က None ဟုတ်မဟုတ် စစ်ဆေးတဲ့ is_pull_request column အသစ်တစ်ခုကို ဖန်တီးနိုင်ပါတယ်။
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)✏️ စမ်းသပ်ကြည့်ပါ။ 🤗 Datasets မှာ issues တွေကို ပိတ်ဖို့ ပျမ်းမျှအချိန်ကို တွက်ချက်ပါ။ pull requests တွေနဲ့ open issues တွေကို filter လုပ်ဖို့
Dataset.filter()function ကို အသုံးဝင်တယ်လို့ တွေ့ရနိုင်ပြီး၊created_atနဲ့closed_attimestamps တွေကို အလွယ်တကူ ကိုင်တွယ်နိုင်ဖို့ dataset ကိုDataFrameအဖြစ် ပြောင်းလဲဖို့Dataset.set_format()function ကို အသုံးပြုနိုင်ပါတယ်။ bonus အမှတ်များအတွက်၊ pull requests တွေကို ပိတ်ဖို့ ပျမ်းမျှအချိန်ကို တွက်ချက်ပါ။
columns အချို့ကို ဖျက်ပစ်ခြင်း သို့မဟုတ် အမည်ပြောင်းလဲခြင်းဖြင့် dataset ကို နောက်ထပ် သန့်ရှင်းရေးလုပ်နိုင်ပေမယ့်၊ ဒီအဆင့်မှာ dataset ကို တတ်နိုင်သမျှ “raw” အဖြစ် ထားရှိခြင်းက နောက်ပိုင်းမှာ applications မျိုးစုံမှာ အလွယ်တကူ အသုံးပြုနိုင်စေဖို့ အလေ့အကျင့်ကောင်းတစ်ခုပါ။
ကျွန်တော်တို့ရဲ့ dataset ကို Hugging Face Hub သို့ push မလုပ်ခင်၊ မပါဝင်သေးတဲ့ အရာတစ်ခုကို ဖြေရှင်းကြည့်ရအောင်- issue နဲ့ pull request တစ်ခုစီနဲ့ ဆက်စပ်နေတဲ့ comments တွေပါ။ ဒါတွေကို နောက်မှာ GitHub REST API နဲ့ ထပ်ထည့်ပါမယ်။
Dataset ကို အဆင့်မြှင့်တင်ခြင်း
အောက်ပါ screenshot မှာ ပြထားတဲ့အတိုင်း၊ issue ဒါမှမဟုတ် pull request တစ်ခုနဲ့ ဆက်စပ်နေတဲ့ comments တွေက အချက်အလက်ကြွယ်ဝတဲ့ အရင်းအမြစ်တစ်ခုကို ပံ့ပိုးပေးပါတယ်။ အထူးသဖြင့် library အကြောင်း အသုံးပြုသူမေးခွန်းတွေကို ဖြေဖို့ search engine တစ်ခု တည်ဆောက်ချင်တယ်ဆိုရင်ပေါ့။
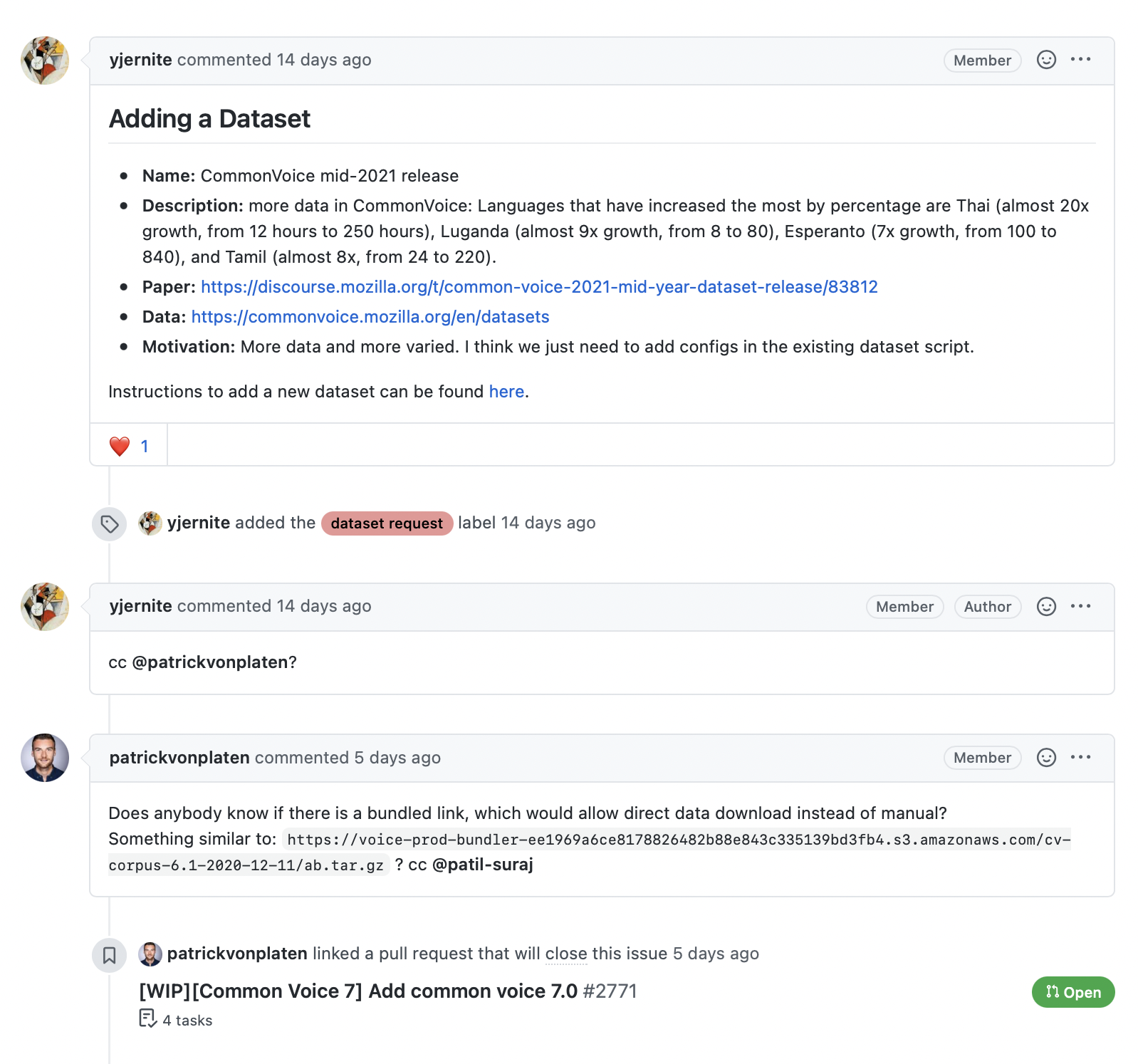
GitHub REST API က issue number တစ်ခုနဲ့ ဆက်စပ်နေတဲ့ comments အားလုံးကို ပြန်ပေးတဲ့ Comments endpoint ကို ပံ့ပိုးပေးပါတယ်။ ဒါက ဘာတွေပြန်ပေးလဲဆိုတာ ကြည့်ဖို့ endpoint ကို စမ်းသပ်ကြည့်ရအောင်။
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]comment က body field ထဲမှာ သိမ်းဆည်းထားတာကို ကျွန်တော်တို့ မြင်နိုင်ပါတယ်။ ဒါကြောင့် response.json() ထဲက element တစ်ခုစီအတွက် body အကြောင်းအရာတွေကို ရွေးထုတ်ပြီး issue တစ်ခုနဲ့ ဆက်စပ်နေတဲ့ comments အားလုံးကို ပြန်ပေးနိုင်တဲ့ ရိုးရှင်းတဲ့ function တစ်ခု ရေးကြည့်ရအောင်။
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# ကျွန်တော်တို့ရဲ့ function က မျှော်လင့်ထားတဲ့အတိုင်း အလုပ်လုပ်မလုပ် စစ်ဆေးပါ
get_comments(2792)["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]ဒါက ကောင်းမွန်ပုံရပါတယ်။ ဒါကြောင့် Dataset.map() ကို အသုံးပြုပြီး ကျွန်တော်တို့ရဲ့ dataset ထဲက issue တစ်ခုစီအတွက် comments column အသစ်တစ်ခု ထည့်လိုက်ရအောင်။
# သင့်အင်တာနက်ချိတ်ဆက်မှုပေါ်မူတည်ပြီး၊ ဒါက မိနစ်အနည်းငယ် ကြာနိုင်ပါတယ်...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)နောက်ဆုံးအဆင့်ကတော့ ကျွန်တော်တို့ရဲ့ dataset ကို Hub သို့ push လုပ်ဖို့ပါပဲ။ ဒါကို ဘယ်လိုလုပ်ရမလဲဆိုတာ ကြည့်ရအောင်။
Dataset ကို Hugging Face Hub သို့ Upload လုပ်ခြင်း
အခု ကျွန်တော်တို့ရဲ့ augmented dataset ကို ရရှိပြီဆိုတော့၊ ဒါကို community နဲ့ မျှဝေနိုင်ဖို့ Hub ကို push လုပ်ရမယ့်အချိန်ပါပဲ။ dataset တစ်ခုကို upload လုပ်တာက အလွန်ရိုးရှင်းပါတယ်- 🤗 Transformers က models တွေနဲ့ tokenizers တွေလိုပဲ၊ dataset တစ်ခုကို push လုပ်ဖို့ push_to_hub() method ကို အသုံးပြုနိုင်ပါတယ်။ ဒါကိုလုပ်ဖို့ authentication token တစ်ခု လိုအပ်ပြီး၊ ဒါကို notebook_login() function နဲ့ Hugging Face Hub ကို အရင်ဆုံး login ဝင်ခြင်းဖြင့် ရရှိနိုင်ပါတယ်။
from huggingface_hub import notebook_login
notebook_login()ဒါက သင် username နဲ့ password ထည့်သွင်းနိုင်မယ့် widget တစ်ခုကို ဖန်တီးပေးပြီး၊ API token ကို ~/.huggingface/token ထဲမှာ သိမ်းဆည်းပါလိမ့်မယ်။ သင် code ကို terminal မှာ run နေတယ်ဆိုရင်၊ CLI မှတစ်ဆင့် login ဝင်နိုင်ပါတယ်။
huggingface-cli login
ဒါကို လုပ်ပြီးတာနဲ့၊ ကျွန်တော်တို့ရဲ့ dataset ကို အောက်ပါအတိုင်း run ပြီး upload လုပ်နိုင်ပါတယ်။
issues_with_comments_dataset.push_to_hub("github-issues")ဒီနေရာကနေ၊ ဘယ်သူမဆို load_dataset() ကို repository ID ကို path argument အဖြစ် ပေးခြင်းဖြင့် dataset ကို download လုပ်နိုင်ပါတယ်။
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})ကောင်းပါပြီ၊ ကျွန်တော်တို့ရဲ့ dataset ကို Hub သို့ push လုပ်ခဲ့ပြီး အခြားသူတွေ အသုံးပြုနိုင်ပါပြီ။ လုပ်ဖို့ကျန်နေသေးတဲ့ အရေးကြီးတဲ့အရာတစ်ခုပဲ ရှိပါတော့တယ်- corpus ကို ဘယ်လိုဖန်တီးခဲ့သလဲဆိုတာကို ရှင်းပြပြီး community အတွက် အခြားအသုံးဝင်တဲ့ အချက်အလက်တွေ ပံ့ပိုးပေးမယ့် dataset card တစ်ခု ထည့်သွင်းခြင်းပါ။
💡
huggingface-cliနဲ့ Git magic အနည်းငယ်ကို အသုံးပြုပြီး terminal ကနေ Hugging Face Hub သို့ dataset တစ်ခုကို တိုက်ရိုက် upload လုပ်နိုင်ပါသေးတယ်။ ဒါကို ဘယ်လိုလုပ်ရမလဲဆိုတာကို Hugging Face 🤗 Datasets guide မှာ ကြည့်ရှုနိုင်ပါတယ်။
Dataset Card တစ်ခု ဖန်တီးခြင်း
ကောင်းမွန်စွာ မှတ်တမ်းတင်ထားသော datasets များသည် အခြားသူများ (သင့်ရဲ့ အနာဂတ် ကိုယ်သင်ကိုယ်တိုင် အပါအဝင်) အတွက် ပိုမိုအသုံးဝင်နိုင်ဖွယ်ရှိပါတယ်။ ဘာကြောင့်လဲဆိုတော့ ၎င်းတို့က dataset သည် ၎င်းတို့ရဲ့ task အတွက် သက်ဆိုင်ခြင်းရှိမရှိ ဆုံးဖြတ်နိုင်ရန်နှင့် dataset အသုံးပြုခြင်းနဲ့ ဆက်စပ်နေတဲ့ ဖြစ်နိုင်ချေရှိသော ဘက်လိုက်မှုများ (biases) သို့မဟုတ် အန္တရာယ်များကို အကဲဖြတ်နိုင်ရန် အချက်အလက်များ (context) ကို ပေးသောကြောင့်ပါ။
Hugging Face Hub မှာ၊ ဒီအချက်အလက်တွေကို dataset repository တစ်ခုစီရဲ့ README.md file ထဲမှာ သိမ်းဆည်းထားပါတယ်။ ဒီ file ကို မဖန်တီးခင် လုပ်ဆောင်သင့်တဲ့ အဓိကအဆင့်နှစ်ဆင့်ရှိပါတယ်။
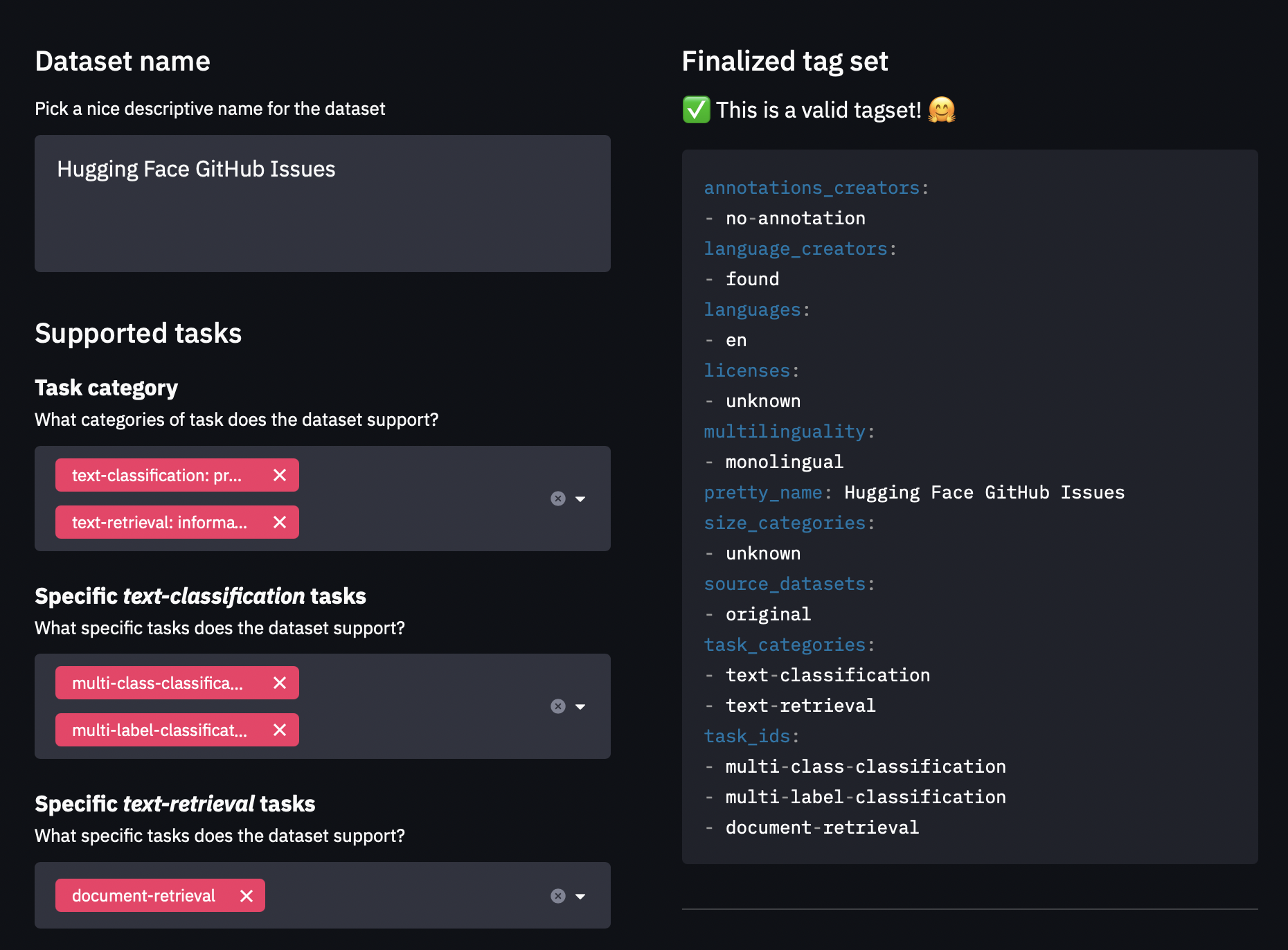
၁။ YAML format နဲ့ metadata tags တွေ ဖန်တီးဖို့ datasets-tagging application ကို အသုံးပြုပါ။ ဒီ tags တွေကို Hugging Face Hub ပေါ်မှာ ရှာဖွေမှု features အမျိုးမျိုးအတွက် အသုံးပြုပြီး သင့် dataset ကို community members တွေက အလွယ်တကူ ရှာဖွေနိုင်ဖို့ သေချာစေပါတယ်။ ဒီနေရာမှာ ကျွန်တော်တို့ custom dataset တစ်ခုကို ဖန်တီးခဲ့တဲ့အတွက်၊ သင် datasets-tagging repository ကို clone လုပ်ပြီး application ကို locally run ဖို့ လိုအပ်ပါလိမ့်မယ်။ interface က ဘယ်လိုပုံလဲဆိုတာ ဒီမှာပါ။
၂။ အချက်အလက်ပြည့်စုံတဲ့ dataset cards တွေ ဖန်တီးခြင်းအကြောင်း 🤗 Datasets guide ကို ဖတ်ပြီး ဒါကို template အဖြစ် အသုံးပြုပါ။
သင် README.md file ကို Hub ပေါ်မှာ တိုက်ရိုက်ဖန်တီးနိုင်ပြီး၊ lewtun/github-issues dataset repository ထဲမှာ template dataset card တစ်ခုကို သင်ရှာတွေ့နိုင်ပါတယ်။ ဖြည့်စွက်ထားတဲ့ dataset card ရဲ့ screenshot တစ်ခုကို အောက်မှာ ပြသထားပါတယ်။

✏️ စမ်းသပ်ကြည့်ပါ။ သင်၏ GitHub issues dataset အတွက် README.md file ကို ဖြည့်စွက်ရန်
datasets-taggingapplication နှင့် 🤗 Datasets guide ကို အသုံးပြုပါ။
ဒါပါပဲ! ဒီအပိုင်းမှာ ကောင်းမွန်တဲ့ dataset တစ်ခု ဖန်တီးတာက အတော်လေး ရှုပ်ထွေးနိုင်တယ်ဆိုတာ ကျွန်တော်တို့ မြင်တွေ့ခဲ့ရပေမယ့်၊ ကံကောင်းစွာနဲ့ပဲ ဒါကို upload လုပ်ပြီး community နဲ့ မျှဝေတာကတော့ မရှုပ်ထွေးပါဘူး။ နောက်အပိုင်းမှာ ကျွန်တော်တို့ရဲ့ dataset အသစ်ကို အသုံးပြုပြီး 🤗 Datasets နဲ့ semantic search engine တစ်ခုကို ဖန်တီးပါမယ်။ ဒါက မေးခွန်းတွေကို အသင့်တော်ဆုံး issues နဲ့ comments တွေနဲ့ ကိုက်ညီစေနိုင်ပါတယ်။
✏️ စမ်းသပ်ကြည့်ပါ။ ဒီအပိုင်းမှာ ကျွန်တော်တို့ လုပ်ခဲ့တဲ့ အဆင့်တွေကို လိုက်နာပြီး သင့်စိတ်ကြိုက် open source library အတွက် GitHub issues dataset တစ်ခု ဖန်တီးပါ။ (🤗 Datasets မဟုတ်တဲ့ တခြားတစ်ခုကို ရွေးချယ်ပါ၊) bonus အမှတ်များအတွက်၊
labelsfield မှာ ပါဝင်တဲ့ tags တွေကို ခန့်မှန်းဖို့ multilabel classifier တစ်ခုကို fine-tune လုပ်ပါ။
ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
- NLP Application: Natural Language Processing (NLP) နည်းပညာများကို အသုံးပြု၍ လူသားဘာသာစကားနှင့် ဆက်စပ်သော လုပ်ငန်းများကို လုပ်ဆောင်သည့် application။
- Corpus: ဘာသာစကားဆိုင်ရာ လေ့လာမှုများအတွက် စုဆောင်းထားသော စာသားအစုအဝေးကြီး။
- GitHub Issues: GitHub repository များတွင် bugs များကို ခြေရာခံရန်၊ features များကို တောင်းဆိုရန် သို့မဟုတ် ပရောဂျက်နှင့် ပတ်သက်သော ဆွေးနွေးမှုများ ပြုလုပ်ရန် အသုံးပြုသော မှတ်တမ်းများ။
- Pull Requests: GitHub တွင် developer များက project code တွင် ပြောင်းလဲမှုများကို အကြံပြုပြီး main codebase ထဲသို့ ပေါင်းစည်းရန် တောင်းဆိုခြင်း။
- Multilabel Classifier: input တစ်ခုကို သတ်မှတ်ထားသော labels များစွာဖြင့် တစ်ပြိုင်နက်တည်း အမျိုးအစားခွဲခြားနိုင်သော machine learning model။
- Metadata: data အကြောင်း အချက်အလက်များ (data about data)။
- Semantic Search Engine: အဓိပ္ပာယ်ပေါ်မူတည်၍ ရှာဖွေမှုများကို လုပ်ဆောင်နိုင်သော search engine။
- Query: search engine တစ်ခုသို့ ပေးပို့သော ရှာဖွေမှု မေးခွန်း။
- 🤗 Datasets: Hugging Face က ထုတ်လုပ်ထားတဲ့ library တစ်ခုဖြစ်ပြီး AI မော်ဒယ်တွေ လေ့ကျင့်ဖို့အတွက် ဒေတာအစုအဝေး (datasets) တွေကို လွယ်လွယ်ကူကူ ဝင်ရောက်ရယူ၊ စီမံခန့်ခွဲပြီး အသုံးပြုနိုင်စေပါတယ်။
- Open Source Project: source code ကို အများပြည်သူအား လွတ်လပ်စွာ အသုံးပြုရန်၊ ပြင်ဆင်ရန်နှင့် မျှဝေရန် ခွင့်ပြုထားသော ဆော့ဖ်ဝဲလ်ပရောဂျက်။
- Repository: Git version control system ကို အသုံးပြု၍ project files တွေကို ခြေရာခံ၊ စီမံခန့်ခွဲရာတွင် အသုံးပြုသော code များ စုစည်းရာနေရာ။
- Issues Tab: GitHub repository တွင် issues များကို စာရင်းပြုစုထားသော tab။
- GitHub REST API: GitHub ပလပ်ဖောင်း၏ ဒေတာများကို ပရိုဂရမ်ဖြင့် ဝင်ရောက်ကြည့်ရှုရန်နှင့် စီမံခန့်ခွဲရန် ခွင့်ပြုသော web service။
IssuesEndpoint: GitHub REST API တွင် issues များနှင့် pull requests များကို ရယူရန် အသုံးပြုသော API endpoint။- JSON Objects: JavaScript Object Notation (JSON) format ဖြင့် ဖော်ပြထားသော data structure များ။
- HTTP Requests: Hypertext Transfer Protocol (HTTP) ကို အသုံးပြု၍ web server မှ အရင်းအမြစ်များကို တောင်းဆိုခြင်း။
requestsLibrary: Python တွင် HTTP requests များ ပြုလုပ်ရန်အတွက် အသုံးပြုသော popular library။pip install requests: Python package managerpipကို အသုံးပြု၍requestslibrary ကို install လုပ်သော command။- GET Request: web server မှ အချက်အလက်များကို ရယူရန် အသုံးပြုသော HTTP request method။
requests.get()Function:requestslibrary မှ GET request တစ်ခုကို ပေးပို့ရန်အတွက် function။responseObject: HTTP request တစ်ခု၏ ရလဒ်များကို ကိုယ်စားပြုသော object။- HTTP Status Code: HTTP request ၏ အခြေအနေကို ဖော်ပြသော ဂဏန်းကုဒ် (ဥပမာ- 200 = OK, 404 = Not Found)။
- Payload: HTTP response ၏ အကြောင်းအရာများ (data)။
- Bytes: ကွန်ပျူတာဖြင့် သိမ်းဆည်းနိုင်သော အသေးငယ်ဆုံး ဒေတာယူနစ်။
- Strings: စာသားကို ကိုယ်စားပြုသော characters များ၏ အစီအစဉ်။
response.json(): HTTP response ၏ payload ကို JSON format ဖြင့် parse လုပ်ပြီး Python dictionary သို့မဟုတ် list အဖြစ် ပြန်ပေးသော method။titleField: issue သို့မဟုတ် pull request ၏ ခေါင်းစဉ်။bodyField: issue သို့မဟုတ် pull request ၏ အဓိက ဖော်ပြချက် သို့မဟုတ် comment ၏ အကြောင်းအရာ။numberField: issue သို့မဟုတ် pull request ၏ ထူးခြားသော နံပါတ်။- Rate Limiting: သတ်မှတ်ထားသော အချိန်ကာလတစ်ခုအတွင်း ပြုလုပ်နိုင်သော requests အရေအတွက်ကို ကန့်သတ်ခြင်း။
per_pageQuery Parameter: API request တစ်ခုတွင် တစ်စာမျက်နှာလျှင် ပြန်ပေးမည့် items အရေအတွက်ကို သတ်မှတ်သော parameter။- Personal Access Token: GitHub API ကို authentication လုပ်ရန် အသုံးပြုသော လုံခြုံရေး token။ ၎င်းသည် rate limit ကို မြှင့်တင်ပေးသည်။
- Request Header: HTTP request တွင် အချက်အလက်များကို ပေးပို့ရန် အသုံးပြုသော key-value pair များ။
AuthorizationHeader: API authentication အတွက် အသုံးပြုသော request header။.envFile: Environment variables များကို သိမ်းဆည်းထားသော ဖိုင်။python-dotenvLibrary:.envfile မှ environment variables များကို Python application သို့ load လုပ်ရန် အသုံးပြုသော library။- Environment Variable: Operating system တွင် သတ်မှတ်ထားသော variable တစ်ခုဖြစ်ပြီး program များက အချက်အလက်များ ရယူရန် အသုံးပြုသည်။
Pathlib: Python တွင် file system paths များကို object-oriented ပုံစံဖြင့် ကိုင်တွယ်ရန် အသုံးပြုသော module။pandas: Python programming language အတွက် data analysis နှင့် manipulation အတွက် အသုံးပြုသော open-source library။tqdm.notebook.tqdm: Notebook environment များအတွက် progress bar ကို ပြသပေးသောtqdmlibrary ၏ function။fetch_issues()Function: GitHub API မှ issues များကို download လုပ်ရန် ကျွန်တော်တို့ ဖန်တီးထားသော function။- Batches: ဒေတာအမြောက်အမြားကို တစ်ပြိုင်နက်တည်း လုပ်ဆောင်နိုင်ရန် အုပ်စုဖွဲ့ထားခြင်း။
DataFrame.from_records(): List of dictionaries မှ Pandas DataFrame တစ်ခုကို ဖန်တီးသော method။to_json(): DataFrame ကို JSON format ဖြင့် file သို့ သိမ်းဆည်းသော method။orient="records": JSON export orientation တစ်မျိုးဖြစ်ပြီး each row is a JSON object။lines=True: JSON Lines format ဖြင့် export လုပ်ရန်အတွက်to_json()argument။jsonl(JSON Lines) File: JSON objects များကို line တစ်ကြောင်းစီတွင် တစ်ခုစီ ထားရှိသော text file format။split="train":load_dataset()function တွင် dataset ၏ training split ကို load လုပ်ရန် သတ်မှတ်ခြင်း။pull_requestKey: GitHub API response တွင် item သည် pull request ဖြစ်မဖြစ် ခွဲခြားရန် အသုံးပြုသော key။Dataset.shuffle(): dataset အတွင်းရှိ rows များကို ကျပန်း (randomly) ရောနှောပေးသော method။Dataset.select(): dataset မှ သတ်မှတ်ထားသော index များကို ရွေးထုတ်ပေးသော method။zip(): Python built-in function တစ်ခုဖြစ်ပြီး iterable objects များကို တွဲဖက်ပေးသည်။html_urlColumn: issue သို့မဟုတ် pull request ၏ web URL။NoneEntry: တန်ဖိုးမရှိခြင်း သို့မဟုတ် မဖော်ပြထားခြင်းကို ကိုယ်စားပြုသော Python object။is_pull_requestColumn: item သည် pull request ဟုတ်မဟုတ်ကို ဖော်ပြသော boolean (True/False) column အသစ်။Dataset.filter(): dataset မှ သတ်မှတ်ထားသော criteria များနှင့် ကိုက်ညီသော rows များကို ဖယ်ရှားပေးသော method။Dataset.set_format(): dataset ၏ output format ကို ပြောင်းလဲပေးသော method (ဥပမာ- “pandas”, “torch”)။created_at/closed_atTimestamps: issue သို့မဟုတ် pull request ဖန်တီးခဲ့သည့် သို့မဟုတ် ပိတ်ခဲ့သည့် ရက်စွဲနှင့် အချိန်။- “Raw” Dataset: မည်သည့် preprocessing သို့မဟုတ် cleaning မှ မလုပ်ရသေးသော dataset။
- Augmenting the Dataset: dataset သို့ အပိုဒေတာများ သို့မဟုတ် အချက်အလက်များ ထပ်ထည့်ခြင်း။
CommentsEndpoint: GitHub REST API တွင် issue တစ်ခု သို့မဟုတ် pull request တစ်ခုနှင့် ဆက်စပ်နေသော comments များကို ရယူရန် အသုံးပြုသော API endpoint။notebook_login()Function (fromhuggingface_hub): Jupyter Notebooks တွင် Hugging Face Hub သို့ authentication လုပ်ရန်အတွက် function။- API Token: API ကို ဝင်ရောက်ကြည့်ရှုရန် အသုံးပြုသော unique key။
~/.huggingface/token: Hugging Face authentication token ကို သိမ်းဆည်းထားသော ဖိုင်လမ်းကြောင်း။huggingface-cli login: Command Line Interface (CLI) မှ Hugging Face Hub သို့ login ဝင်ရန် command။- Repository ID: Hugging Face Hub ပေါ်ရှိ repository တစ်ခု၏ ထူးခြားသော ID (ဥပမာ-
lewtun/github-issues)။ - Dataset Card: Hugging Face Hub တွင် dataset တစ်ခုစီအတွက် ပါရှိသော အချက်အလက်များပါသည့် စာမျက်နှာ (README.md file)။ ၎င်းတွင် dataset ကို မည်သို့ဖန်တီးခဲ့သည်၊ ၎င်း၏ ကန့်သတ်ချက်များ၊ ဘက်လိုက်မှုများ (biases) နှင့် အသုံးပြုနည်းများ ပါဝင်သည်။
- Context: အချက်အလက် သို့မဟုတ် အခြေအနေတစ်ခုကို နားလည်ရန် အရေးကြီးသော နောက်ခံအချက်အလက်။
- Potential Biases: dataset တွင် ဖြစ်ပေါ်နိုင်သော ဘက်လိုက်မှုများ။
- Risks: dataset အသုံးပြုခြင်းနှင့် ဆက်စပ်သော ဖြစ်နိုင်ချေရှိသော အန္တရာယ်များ။
datasets-taggingApplication: Hugging Face မှ dataset ၏ metadata tags များကို ဖန်တီးရန် ကူညီပေးသော application။- YAML Format: Human-readable data serialization standard တစ်ခုဖြစ်ပြီး configuration files များတွင် အသုံးများသည်။
- Metadata Tags: dataset ကို ရှာဖွေနိုင်ရန်နှင့် အမျိုးအစားခွဲခြားရန် အသုံးပြုသော keywords သို့မဟုတ် labels များ။
- Clone: Git repository တစ်ခု၏ မိတ္တူအပြည့်အစုံကို local machine သို့ download လုပ်ခြင်း။
- Local Machine: သင်အသုံးပြုနေသော ကိုယ်ပိုင်ကွန်ပျူတာ။
- Semantic Search Engine: အဓိပ္ပာယ်ပေါ်မူတည်၍ ရှာဖွေမှုများကို လုပ်ဆောင်နိုင်သော search engine။