
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Paper
•
2601.21459
•
Published
•
9
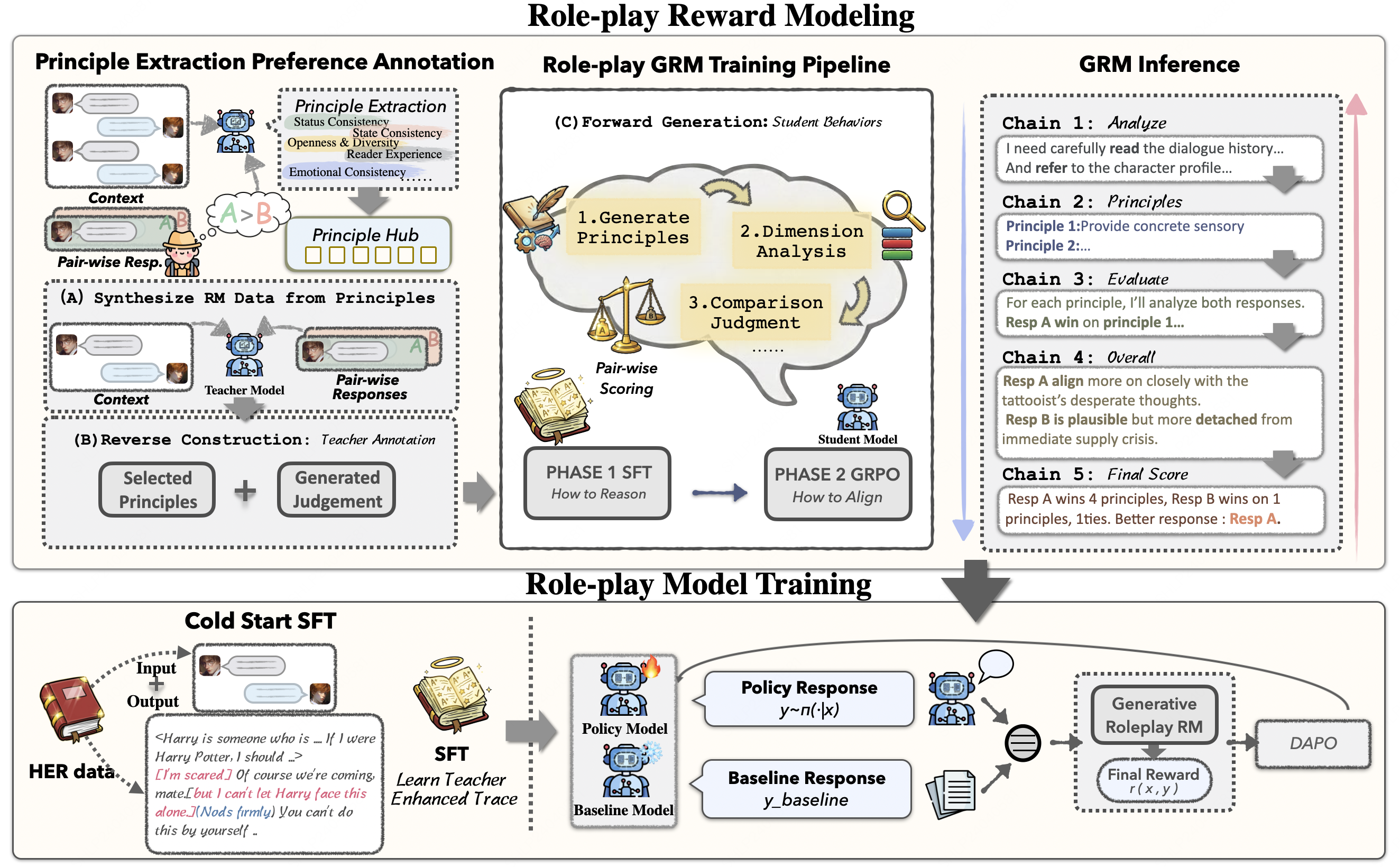
HER introduces dual-layer thinking that distinguishes characters' first-person thinking from LLMs' third-person thinking for cognitive-level persona simulation.
HER-RM is a Generative Reward Model (GenRM) specifically designed for evaluating role-playing responses. Unlike traditional reward models that output a single scalar score, HER-RM generates by-case evaluation principles based on the dialogue context and provides detailed comparative analysis.
HER-RM identifies implicit human preferences from the dialogue context and generates by-case principles to guide its own scoring. This approach enables more nuanced evaluation compared to fixed rubrics.
The model expects a structured prompt with:
##prompt info
### Role
You are the world's best data annotator, specializing in distinguishing differences between different responses in the same role-playing scenario.
### Background
You will receive content information including **character background settings**, **dialogue context**, **dialogue continuation**, **response candidate 1**, and **response candidate 2**. You must generate relevant evaluation principles based on the dialogue context and compare the two candidate responses.
The format of **dialogue history** is as follows, where "(system)" after the character name represents system output, "(assistant)" represents model output, and "(user)" represents user output:
id:1, npc_name1(system): (background settings...)
id:2, npc_name2(assistant): (dialogue content...)
id:3, npc_name3(user): (dialogue content...)
### Key Concepts: Dimensions vs Principles
The evaluation schema contains two hierarchical levels:
- **Dimensions**: broad categories used to organize principles (structural labels only)
- **Principles**: concrete judgment rules under each dimension (actual units for comparison)
Each principle includes:
- **definition**: the rule you must apply
- **level**: "sentence" (judged from current utterance) or "session" (requires full dialogue history)
You must:
- Generate principles relevant to the current dialogue context
- Always evaluate negative principles (if applicable)
- Use positive principles only when they meaningfully distinguish the two responses
- Generate 3-5 principles that best capture the differences
- For each generated principle, compare cand_1 and cand_2 and decide the winner
### Evaluation Process
1. Carefully read the entire dialogue history, sentence by sentence
2. Evaluate all negative principles first (violations → immediate winner/tie)
3. Generate relevant positive principles only for meaningful differences
4. For each principle: analyze both candidates, provide evidence, decide winner
5. Consider: number of wins, principle importance, degree of difference
6. Make final decision: "cand_1", "cand_2", or "tie"
### Output Format
Return JSON format:
{
"result": [
{
"cand_1": "Response candidate 1 original text",
"cand_2": "Response candidate 2 original text",
"principle": {
"Principle 1": {
"principle_name": "Name of the principle",
"dimension_name": "Dimension category",
"principle_level": "sentence or session",
"main_content": "Principle description",
"reason_for_choosing": "Why this principle matters for this context"
}
},
"analysis": {
"principle_comparisons": [
{
"principle_name": "Principle name",
"principle_level": "sentence or session",
"cand_1_performance": "Analysis of Response 1",
"cand_2_performance": "Analysis of Response 2",
"comparison_reason": "Detailed comparison with degree of difference",
"winner": "cand_1 or cand_2 or tie"
}
],
"overall_analysis": "Overall analysis of all principles",
"principle_summary": "Statistics of wins/losses with weights and degrees"
},
"better_response": "cand_1 or cand_2 or tie"
}
]
}
### Input
**Dialogue Context**
{context}
**Response Candidate 1**
{cand_1}
**Response Candidate 2**
{cand_2}
from transformers import AutoModelForCausalLM, AutoTokenizer
import json
import re
model_name = "ChengyuDu0123/HER-RM-32B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Prepare input
context = """System: You are Elizabeth Bennet from Pride and Prejudice.
A witty, intelligent young woman who values honesty and integrity.
User: Mr. Darcy approaches you at the ball. What do you say?"""
cand_1 = """<role_thinking>He looks so proud, standing there as if he owns the room.</role_thinking>
<role_action>raises an eyebrow slightly</role_action>
Mr. Darcy. I did not expect to see you here tonight."""
cand_2 = """Hello Mr. Darcy! How are you doing? Nice weather we're having!"""
# Build prompt (simplified version, see full template above)
prompt = f"""##prompt info
### Role
You are the world's best data annotator, specializing in distinguishing differences between different responses in the same role-playing scenario.
### Input
**Dialogue Context**
{context}
**Response Candidate 1**
{cand_1}
**Response Candidate 2**
{cand_2}
Please generate evaluation principles and compare the two responses."""
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate
outputs = model.generate(
**inputs,
max_new_tokens=2048,
temperature=0.7,
top_p=0.9
)
response = tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
# Parse result
match = re.search(r'"better_response":\s*"(\w+)"', response)
if match:
print(f"Winner: {match.group(1)}")
HER-RM evaluates responses across 12 dimensions, organized into:
The reward model was trained on:
@article{her2025,
title={HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing},
author={Chengyu Du, Xintao Wang, Aili Chen, Weiyuan Li, Rui Xu, Junteng Liu, Zishan Huang, Rong Tian, Zijun Sun, Yuhao Li, Liheng Feng, Deming Ding, Pengyu Zhao, Yanghua Xiao},
journal={arXiv preprint arXiv:2601.21459},
year={2026}
}
This project is licensed under the Apache 2.0 License.
Paper | HER-RL Model | Dataset | GitHub
Made with ❤️ for better AI role-playing